Which Word is the Most Biblical?
November 16, 2016 - Python and WebcrawlingMy friend, Kyle, is writing a novel and I've been helping him out by reading drafts and passing along feedback. In one of the recent drafts, I noted that the draft seemed to be very heavy on names for minor characters, which made the draft seem very dense and tough to keep up with. As he and I discussed it further, we brainstormed an idea for a tool that could go through the text and highlight certain words, so it's easy to scroll through and see how often a word appears. After a few beers, this idea snowballed into a tool that would find the most common words in the text and highlight them. With that in mind, I ran off to my machine and began stitching together the code that makes up the heart of this project. It turns out that the code is quite flexible, so besides asking "what are the most common words in Kyle's novel," I could also ask the same thing of any other source of text. What's the most common word in the Bible? What's the most common word used by Donald Trump on Twitter? These are questions that can all be answered by the modules I've designed.
Getting the Text
A problem common to every person who's ever worked on data analysis: how do I get my data? In this case, it could have been simple enough to ask Kyle for text files, but if I wanted this to be more flexible, I needed to expand the methods. So instead, I built my first webcrawler. Kyle's novel is hosted on his website, so I used a webcrawler with the BeautifulSoup library to extract the text straight out of his website. This same webcrawler was also used to get the full text of the King James Version of the Bible that is freely available at the Gutenberg Project.I also thought it would be fun to be able to search Twitter and extract the most common words related to either a) a user or b) a search item. So I connected to the Twitter API using Twython and implemented a search function into the program to extract the text from the tweets pulled by the API during the search.
In practice, this is the only part of the code that changes for each different application. The user must get a text source and feed it to the rest of the code chain. Once the source is found the text is split into individual words, punctuation is removed, and capital letters are de-cased so that both "With" and "with" are counted as the same word. A second copy of the words is also stored as a string, keeping the punctuation and capitalization in-tact for the purposes of reconstructing the text with words highlighted later. An example of the implementation is shown below.
from bs4 import BeautifulSoup
import requests
import wordCountMaker as wcm #This is the module contains project-specific functions
html = requests.get(url).text #Get all html text from url
soup = BeautifulSoup(html, 'html5lib') #Use BS4 to break apart tags
for x in soup.findAll("p"): #Get all text in any <p> tag
if wcm.is_title_text(x.text): #Remove titles from text block
continue
for word in x.text.strip().split(): #Split into words
unfiltered_wordlist.append(word) #Keep raw words for later
if wcm.filter_common_words(word.lower()): #Function to remove common words
continue
wordlist.append(wcm.clean_word_for_count(word)) #Clean the words and store
import requests
import wordCountMaker as wcm #This is the module contains project-specific functions
html = requests.get(url).text #Get all html text from url
soup = BeautifulSoup(html, 'html5lib') #Use BS4 to break apart tags
for x in soup.findAll("p"): #Get all text in any <p> tag
if wcm.is_title_text(x.text): #Remove titles from text block
continue
for word in x.text.strip().split(): #Split into words
unfiltered_wordlist.append(word) #Keep raw words for later
if wcm.filter_common_words(word.lower()): #Function to remove common words
continue
wordlist.append(wcm.clean_word_for_count(word)) #Clean the words and store
Making the Word Count/Plot
From there, it was a fairly simple matter to just create a dictionary that counts the number of times a word appears, after splitting the text into individual words and removing any uppercase specific splitting. However, this naive implementation returned something I should have expected... the most common words are always "a, an, the, I, for, ..." It turns out that a filter is pretty necessary to separate meaningful words from chaf. So I wrote a function that filters out the most common words:
def filter_common_words(w):
common_words = ['a', 'the', 'an', 'to', 'and', 'for', 'of', 'is', 'that', 'it', 'on', 'you', 'with', 'are', 'my', 'if', 'at', 'as', 'by', 'was', 'be', 'but', 'were', 'had']
if w in common_words:
return True
else:
return False
common_words = ['a', 'the', 'an', 'to', 'and', 'for', 'of', 'is', 'that', 'it', 'on', 'you', 'with', 'are', 'my', 'if', 'at', 'as', 'by', 'was', 'be', 'but', 'were', 'had']
if w in common_words:
return True
else:
return False
After filtering these common words, I had a nice dictionary that includes every word in the text, as well as the number of times it appears. To help visualize this, I prepared this dictionary to be plotted as a bar plot and then plotted the 60 most common words, colorizing the words based on their frequency.
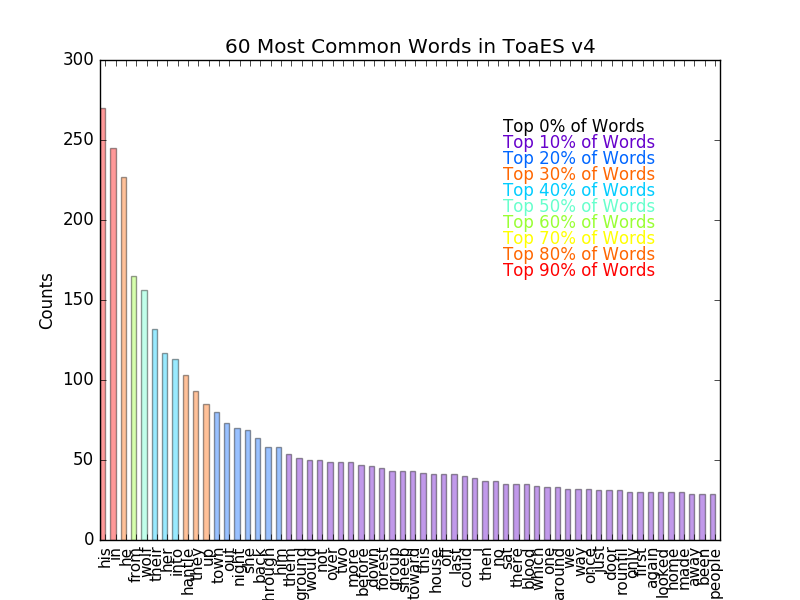
Making a Webpage
The ultimate goal of this was to find the common words and then reprint the text with the common words highlighted. One of the simplest ways to do that is to make a HTML page that contains the text, applying the correct colorization and highlighting tags on a word-by-word basis. This is why we saved the "unfiltered words" in the example above, so that we can use them again with their original formatting. This makes for a large HTML file, but it actually works quite well. An example is shown below using the text from some Donald Trump tweets (all politics aside, I chose him because he was in the news at the time for tweeting).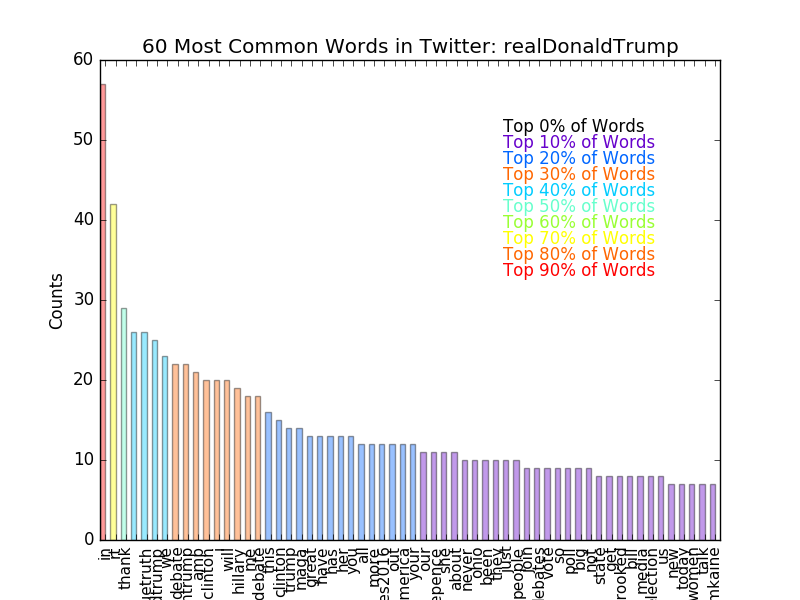
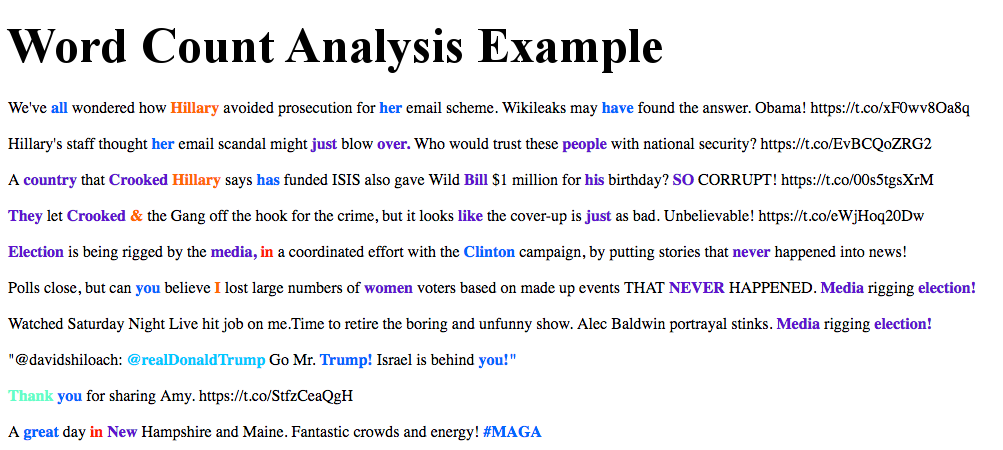 The color scheme is shared between the plot and the page. So we can first quickly scan through the plot and see what the common words are, then scan through the text and see where all these words are. The full example page can be found here: Colorized Trump Tweets.
The color scheme is shared between the plot and the page. So we can first quickly scan through the plot and see what the common words are, then scan through the text and see where all these words are. The full example page can be found here: Colorized Trump Tweets.
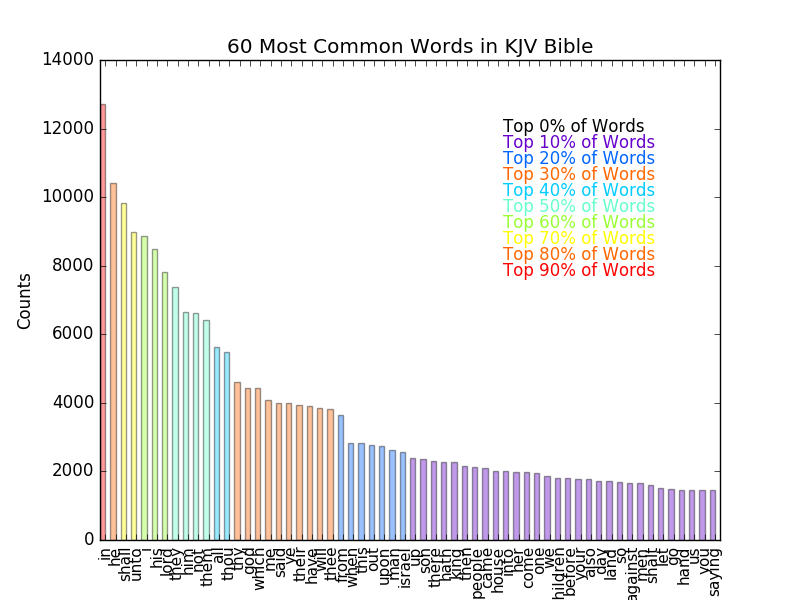
So What is the Most Common Biblical Word?
For the KJV version of the bible hosted on Gutenberg's website, the most common word is "in." That may seem a cheap one, but I didn't filter it because it's often necessary in a sentence. For example the previous sentence would read, "...it's often necessary a sentence," and I tried not to filter words that could be necessary. If we want to take the first "non-cheap" words, "he" and "shall" are the next two in line. The most common "bible-y" word is "lord," which comes in as the 7th most common word. The full plot is shown below.