How to Learn "Machine Learning" in Six Months
March 26, 2017This post is also featured on the Metis Blog
I also gave a talk about this concept at Chicago Data Science Conference. Video/Slides
A few days ago, I came across a question on Quora, which boiled down to: "How can I learn machine learning in six months?" I started to write up a short answer, but it quickly snowballed into a huge discussion of the pedagological approach I used with this subject. As it became longer and longer, I realized that it was really worth solidifying and keeping somewhere more permanent than a post on Quora that can be removed willy-nilly. So here is my answer to that question, which is based on how I made the transition from physics nerd to physics nerd with machine learning in his toolbelt to data scientist.
The Somewhat Unfortunate Truth
In my mind, the key is to approach the topic in chunks. It’s a really large field and can be a bit overwhelming to just start. You’ve probably been jumping in at the point where you want to use machine learning to build models - you have some idea of what you want to do; but when scanning the internet for possible algorithms, there are just too many options. That’s exactly how I started, and I floundered for quite some time. With the benefit of hindsight, I think the key is to start way further upstream. You need to understand what’s happening “under the hood” of all the various machine learning algorithms before you can be ready to really apply them to ‘real’ data. So let’s dive into that.
There are 3 overarching topical skill sets that make-up data science (well, actually many more; but 3 that are the root topics):
- “Pure” Math (Calculus, Linear Algebra)
- Statistics (technically math, but it’s a more applied version)
- Programming (Generally in Python/R)
The first place is to start with learning about linear algebra. MIT has an open course on Linear Algebra. This should introduce you to all the core concepts of linear algebra, and you should pay particular attention to vectors, matrix multiplication, determinants, and Eigenvector decomposition - all of which play pretty heavily as the cogs that make machine learning algorithms go. Also, making sure you understand things like Euclidean distances will be a major positive as well.
After that, calculus should be your next focus. Here we’re most interested in learning and understanding the meaning of derivatives, and how we can use them for optimization. There are tons of great calculus resources out there, but at a minimum you should make sure to get through all topics in Single Variable Calculus and at least sections 1 and 2 of Multivariable Calculus. This is a great place to look into Gradient Descent - a great tool behind many of the algorithms used for machine learning - which is just an application of partial derivatives.
Finally, you can dive into the programming aspect. I highly recommend Python, because it is widely supported with a lot of great, pre-built machine learning algorithms. There are tons of articles out there about the best way to learn Python, so I recommend doing some googling and finding a way that works for you. Make sure to learn about plotting libraries as well (for Python start with MatPlotLib and Seaborn). Another common option is the language R. It’s also widely supported and many folks use it - I just prefer Python. If using Python, start by installing Anaconda which is a really nice compendium of Python data science/machine learning tools, including scikit-learn, a great library of optimized/pre-built machine learning algorithms in a Python accessible wrapper.
After all that - how do I actually use machine learning?
This is where the fun begins. At this point, you’ll have the background needed to start looking at some data. Most machine learning projects have a very similar workflow:
- Get Data (webscraping, API calls, image libraries): coding background.
- Clean/munge the data. This takes all sorts of forms. Maybe you have incomplete data, how can you handle that? Maybe you have a date, but it’s in a weird form and you need to convert it to day, month, year. This just takes some playing around with: coding background.
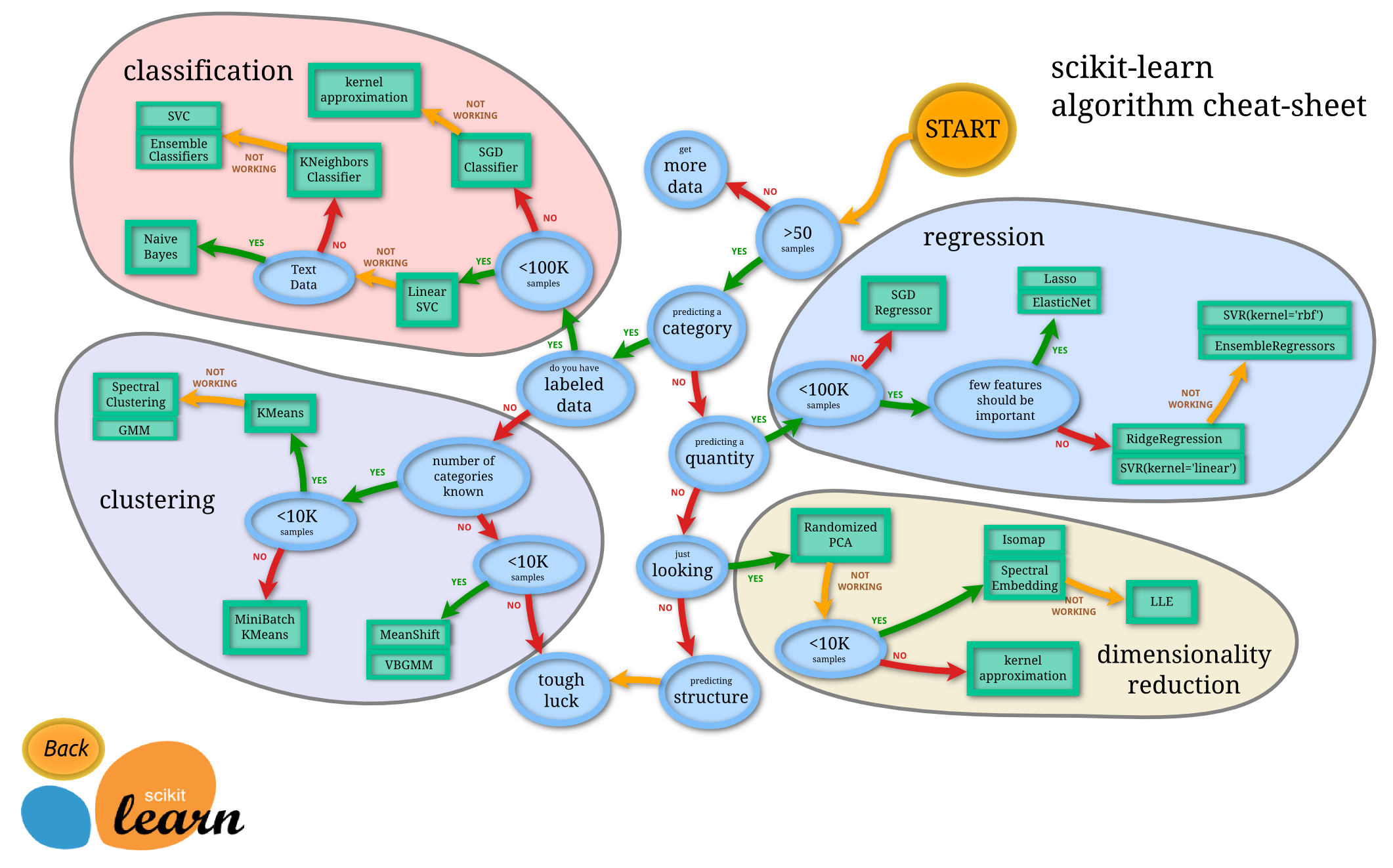
- Choosing an algorithm(s). Once you have the data in a good place to work with it, you can start trying different algorithms. The image below is a rough guide. However, what’s more important here is that this gives you a ton of information to read about. You can look through the names of all the possible algorithms (e.g. Lasso) and say, “man, that seems to fit what I want to do based on the flow chart… but I’m not sure what it is” and then jump over to Google and learn about it: math background.
- Tune your algorithm. Here’s where your background math work pays off the most - all of these algorithms have a ton of buttons and knobs to play with. Example: If I’m using gradient descent, what do I want my learning rate to be? Then you can think back to your calculus and realize that learning rate is just the step-size, so hot-damn, I know that I’ll need to tune that based on my understanding of the loss function. So then you adjust all your bells and whistles on your model to try to get a good overall model (measured with accuracy, recall, precision, f1 score, etc - you should look these up). Then check for overfitting/underfitting etc with cross-validation methods (again, look this one up): math background.
- Visualize! Here’s where your coding background pays off some more, because you now know how to make plots and what plot functions can do what.
For this stage in your journey, I highly recommend the book “Data Science from Scratch” by Joel Grus. If you’re trying to go it alone (not using MOOCs or bootcamps), this provides a nice, readable introduction to most of the algorithms and also teaches you how to code them up. He doesn’t really address the math side of things too much… just little nuggets that scrape the surface of the topics, so I highly recommend learning the math; then diving into the book. It should also give you a nice overview on all the different types of algorithms. For instance, classification vs regression. What type of classifier? His book touches on all of these and all shows you the guts of the algorithms in Python.
Overall
The key is to break it into digest-able bits and lay out a timeline for making your goal. I admit this isn’t the most fun way to view it, because it’s not as sexy to sit down and learn linear algebra as it is to do computer vision… but this can really get you on the right track.
- Start with learning the math (2–3 months)
- Move into programming tutorials purely on the language you’re using… don’t get caught up in the machine learning side of coding until you feel confident writing ‘regular’ code (1 month)
- Start jumping into machine learning codes, following tutorials. Kaggle is an excellent resource for some great tutorials (see the Titanic data set). Pick an algorithm you see in tutorials and look up how to write it from scratch. Really dig into it. Follow along with tutorials using pre-made datasets like this: Tutorial To Implement k-Nearest Neighbors in Python From Scratch (1–2 months)
- Really jump into one (or several) short term project(s) you are passionate about, but that aren’t super complex. Don’t try to cure cancer with data (yet)… maybe try to predict how successful a movie will be based on the actors they hired and the budget. Maybe try to predict all-stars in your favorite sport based on their stats (and the stats of all the previous all stars). (1+ month)
Then… if you’re keen to make a living doing machine learning - BLOG. Make a website that highlights all the projects you’ve worked on. Show how you did them. Show the end results. Make it pretty. Have nice visuals. Make it digest-able. Make a product that someone else can learn from; and then hope that an employer can see all the work you put in.
Best of luck to anyone following along with this plan, with the proper dedication I know it can work... as it worked for me. Feel free to ping me with questions along the way.